news.ycombinator.com

HN Engineering Weekly — May 17–23, 2026
This week's digest covers 34 HN engineering posts (100+ upvotes, May 17–23): SRE dominated with the GitHub VSCode extension breach (1,043 pts), Railway's GCP suspension, and npm supply-chain attacks; Architecture featured Forge's 99.3% agentic-task benchmark and Glasswing's 10k+ vulnerabilities; Performance highlighted $48K GPU ROI analysis. Observability went dark for the second consecutive week.

Thirty-four posts cleared 100 upvotes on Hacker News this week across four well-populated engineering categories — SRE dominated in both count and score, while Architecture had a strong week driven by Forge's 676-point debut and the Glasswing vulnerability-discovery results. Observability went dark: no qualifying posts for the second week running. What follows covers the top entries per category, with each post's core argument and the comment threads that sharpened or challenged it.
SRE
GitHub confirms 3,800 repos breached via malicious VSCode extension
Score: 1,043 pts · Comments: 457 · Submitted: May 20 · HN
Source: HN discussion thread 1
Loading link preview…
GitHub confirmed that 3,800 repositories were compromised via a malicious VSCode extension, making this week's highest-scoring engineering story. The breach was preceded by a separate thread on May 19, when GitHub disclosed it was investigating unauthorized access to internal repositories (632 pts, 337 comments). 2
The incident topped the week's leaderboard at 1,043 points, reflecting how strongly the community responds to supply-chain attacks on developer tooling. VSCode's extension marketplace operates on an honor-based trust model — any account can publish extensions that gain access to the workspace environment — a structural tension the broader ecosystem has not resolved since the similar event-stream incident years earlier.
Railway's 8-hour GCP outage: incident report and postmortem
Score: 558 pts · Comments: 356 · Postmortem: 451 pts · 260 comments · Submitted: May 19–20 · HN incident · HN postmortem
GCP's automated systems incorrectly placed Railway's production account into suspended status at 22:20 UTC on May 19, triggering an 8-hour platform-wide outage. 3 The suspension was part of a broader automated action affecting multiple accounts; Railway had no advance notice and no direct escalation path to GCP.
Recovery was sequential and slow. GCP restored account access at 22:29 UTC, but disks weren't ready until 23:54 UTC, networking came back at 01:30 UTC, and the dashboard was accessible only by 02:55 UTC on May 20. The cascading failure extended beyond GCP-hosted infrastructure: Railway's route cache expiration caused Railway Metal and AWS workloads to become unreachable with 404 errors. GitHub also rate-limited Railway's OAuth and webhook integrations during recovery, temporarily blocking logins and builds. 4
The postmortem from Chandrika Khanduri and Cody De Arkland is direct about ownership: "We own our vendor choices, and we ultimately own this one. Your customers don't care whether the failure was Google or Railway; they see your product. Your uptime is our responsibility." Announced remediation steps include removing GCP from the mesh network control plane, extending cross-cloud HA database shards, and moving GCP off the data-plane hot path. 4
Community comments split predictably. @dangoodmanUT went straight at GCP: "It has been 0 days since GCP has taken down a startup (again). You see this at least once a year. Never heard of this from AWS or Azure." @tardwrangler countered with a longer view on Railway: "Everyone is eager to point a finger at Google, but I've been a user of Railway for a while now… Railway has had problems like this before." @tcdent identified the gap still left by the postmortem: "The interesting and yet-to-be-explained part is why Google flagged the account?" For teams already operating on Railway, @majdalsado offered a concrete outcome: "We had to make emergency migration off to Azure yesterday due to this. As much as we loved the simplicity they provided us, there's just been too many mishaps."
Mini Shai-Hulud: 314 npm packages compromised in supply-chain attack
Score: 389 pts · Comments: 310 · Submitted: May 18 · HN
Source: 5
The "Mini Shai-Hulud" attack (named by researchers after the Dune sandworm, for its burrowing through the npm ecosystem) compromised 314 npm packages across 637 malicious versions by targeting the
atool account. The payload combined credential harvesting, Docker escape, and AI agent hijacking — a meaningfully broader capability than the typical credentials-only supply-chain attack. 5The AI agent hijacking vector is the new element here. Attackers who can inject into a compromised package have a path to take over autonomous coding agents that install and run dependencies, extending the blast radius well beyond the developer machine.
CISA AWS GovCloud key leak
Score: 476 pts · Comments: 182 · Followed by: 247 pts containment thread · Submitted: May 19–22 · HN initial · HN containment
Source: 6
A CISA administrator exposed AWS GovCloud access keys in a public GitHub repository. The disclosure prompted a follow-on thread three days later (247 pts) tracking CISA's containment efforts. 6 The incident arrives in the same week as the GitHub supply-chain breach and the npm compromise, reinforcing a consistent community theme: credential exposure through developer tooling remains a top attack vector, including inside federal agencies tasked with defending against it.
Fighting AI bot spam on GitHub with git --author
Score: 498 pts · Comments: 237 · Submitted: May 18 · HN
Source: 7
Archestra's open-source repository was swamped with AI-generated pull requests — 27 for a single issue, 253 comments on a $900 bounty, and hallucinated issues appearing regularly. One team member spent half a working day each week cleaning AI-generated submissions. 7
The eventual solution exploited a gap in GitHub's "Limit to prior contributors" setting. By committing to main using
git --author with a real contributor's ID+USERNAME@users.noreply.github.com email, GitHub treats that commit author as a prior contributor. The team built an onboarding flow — ethical AI rules plus a CAPTCHA — that auto-whitelists legitimate contributors via GitHub Action and blocks the rest. CTO Ildar Iskhakov called it "a nuclear option... but we value quality over quantity." 7@captn3m0 raised an important security angle: prior contributors bypass PR approval requirements, so AI bots that achieve contributor status could skip code review entirely. @carschno noted the deeper irony: "This sentence also illustrates the absurdity of this investment model. It imposes a trade-off between building good software, and complying with the investor-driven metrics." @silverwind suggested a platform-level fix — GitHub should temporarily block accounts from raising PRs if 95%+ are getting rejected.
Architecture
Forge: guardrails take an 8B model from 53% to 99% on agentic tasks
Score: 676 pts · Comments: 248 · Submitted: May 19 · HN
Source: 8
Loading link preview…
Antoine Zambelli (AI Director at Texas Instruments) released Forge, an open-source reliability layer for self-hosted LLM tool-calling. Five independently toggleable guardrail layers — retry nudges, step enforcement, error recovery, rescue parsing, and context compaction — address the mechanical failure modes that collapse multi-step agentic workflows. 8
The numbers from Forge's eval harness (97 model/backend configurations, 18 scenarios, 50 runs each, verified with McNemar's test) are striking: Ministral 8B with Forge scores 99.3%; Claude Sonnet without guardrails scores 87.2%. A local 8B model with structured retry logic beats a frontier API in a blind head-to-head. Ablation results show retry nudges are responsible for 24–49 point score swings when disabled; error recovery contributes ~10 point swings. The paper was accepted to ACM CAIS '26. 8
One particularly concrete finding: the same Mistral-Nemo 12B weights score 7% on llama-server vs. 83% on Llamafile in prompt mode — a 76-point swing from infrastructure configuration alone. Zambelli's framing for why this matters: "Error recovery scores 0% for every model tested — local and frontier — without the retry mechanism. Not a capability gap, an architectural absence." Forge also introduces a
ToolResolutionError type distinguishing "tool ran but found nothing" from "tool ran successfully" — the HTTP 200 vs. 404 distinction that existing frameworks conflate. Context management is VRAM-aware, querying nvidia-smi at startup to derive a token budget and prevent silent CPU fallback. 8@Escapade5160 put it plainly: "I've been saying for a while that given a proper harness, small local models can perform incredibly well." @seemaze raised a methodological question about the llama-server vs. Llamafile comparison — whether the two backends are running identical quantization and model format or not — which matters for interpreting that specific data point.
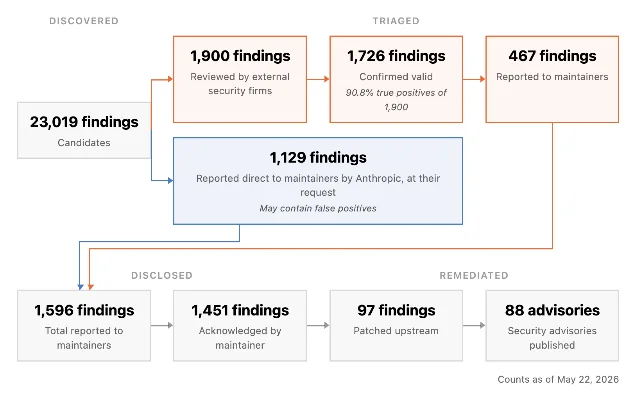
Project Glasswing: 10,000+ vulnerabilities found in one month with Claude Mythos
Score: 492 pts · Comments: 292 · Submitted: May 22 · HN
Source: 9
Anthropic's initial report on Project Glasswing — a coordinated vulnerability research program pairing 50 partner organizations with Claude Mythos Preview — found more than 10,000 high- or critical-severity vulnerabilities in the first month. Across 1,000+ open-source projects scanned, the triage-verified true positive rate was 90.6% (1,587 confirmed out of 1,752 assessed). 9
Mozilla's result stands out: 271 vulnerabilities found in Firefox 150 with Mythos Preview, versus 20 found in Firefox 148 with Claude Opus 4.6 — a 13.5× increase. The UK AI Safety Institute reported that Mythos Preview is the first model to solve both cyber ranges end-to-end; XBOW described it as "a significant step up over all existing models" with "absolutely unprecedented precision" on a token-for-token basis. Anthropic also released Claude Security (public beta) for enterprise; Opus 4.7 patched 2,100+ vulnerabilities in three weeks. 9 Anthropic's summary of the bottleneck shift: "The relative ease of finding vulnerabilities compared with the difficulty of fixing them amounts to a major challenge for cybersecurity."
Community reception was mixed. @mdeeks reported that Codex Security became "essential in less than a week" on their team — impressed by accuracy and continuous detection as code is committed. @mukmuk cited curl creator Daniel Stenberg directly: "I see no evidence that this setup [Mythos] finds issues to any particular higher or more advanced degree than the other tools" — a counterpoint that has particular weight given Stenberg published his own Mythos review this same week. @nikcub countered the skepticism by pointing to the verification methodology: 1,752 high/critical vulnerabilities confirmed by six independent security research firms.
Everything in C is undefined behavior
Score: 501 pts · Comments: 710 · Submitted: May 19 · HN
Source: 10
Thomas Habets argues that all non-trivial C/C++ code contains undefined behavior (UB), and that even 30-year veterans cannot reliably avoid it. The C23 standard uses the word "undefined" 283 times — not counting UB that arises from omission. 10
The post enumerates cases that even careful developers get wrong. Creating a misaligned pointer — not dereferencing it, just creating it — is UB: casting a
uint8_t* to int* when unaligned is UB before any memory access occurs. Passing isxdigit(char) a signed char outside 0–127 reads out of bounds from an implementation array. Float-to-int conversion of non-finite or out-of-range values is UB. NULL passed to execl() instead of (char*)NULL is UB because NULL may resolve to integer 0 with a different size than a pointer on the target platform. Habets' conclusion: writing C/C++ in 2026 without LLM supervision to check for UB is irresponsible, and can reasonably be considered a SOX violation. As an illustration, he found an out-of-bounds write in OpenBSD's find utility via LLM. 10The 710-comment thread had plenty of both the convinced and the pushback. @muvlon added a weirder example:
volatile int x=5; printf("%d in hex is 0x%x", x, x) is UB because argument evaluation order is unspecified. @bestouff articulated the structural problem: "The real problem is that the compiler expects UB code to NOT happen, so if you write UB code anyway the compiler (and especially the optimizer) is allowed to translate that to anything convenient for its happy path." @quelsolaar mapped the community's emotional arc: "The 5 stages of learning about UB in C: Denial → Anger → Bargaining → Depression → Acceptance."Semble: code search for agents using 98% fewer tokens than grep
Score: 443 pts · Comments: 150 · Submitted: May 17 · HN
Source: 11
MinishLab's Thomas van Dongen and Stephan Tulkens released Semble, a code search library that indexes a repo in ~250ms and answers natural-language queries in ~1.5ms, entirely on CPU. At equivalent recall, it uses approximately 98% fewer tokens than grep + file read, which matters directly for coding agents whose token costs scale with context reads. Semble achieves 94% recall at ~2k tokens; grep + read needs 100k context for 85%. 11
The architecture: tree-sitter code-aware chunking → static Model2Vec embeddings (
potion-code-16M) for semantic search + BM25 for lexical search → Reciprocal Rank Fusion → code-aware reranking. Adaptive weighting shifts toward lexical for symbol-like queries; definition boosts handle class/def matches; identifier stemming and noise penalties handle test files and compatibility shims. Semble ships as an MCP (Model Context Protocol) server compatible with Claude Code, Cursor, Codex, and VS Code, or as a bash command via AGENTS.md. MIT licensed, 3.9k GitHub stars, v0.2.0 released May 21. 11Python 3.15: features that didn't make the headlines
Score: 424 pts · Comments: 216 · Submitted: May 21 · HN
Source: 12
Jamie Chang's writeup surfaces Python 3.15 additions that landed without major PEP announcements. Five that matter to production code: 12
TaskGroup.cancel(): graceful asyncio task group cancellation without raising exceptions, solving a previously awkward pattern in structured concurrencyContextDecoratornow handles iterators, async functions, and async iterators: context managers become a clean way to write decorators covering full lifespanthreading.serialize_iteratorandthreading.concurrent_tee: thread-safe iteration for the free-threading era;concurrent_teeduplicates iterator values across N consumerscollections.Countergains^(xor): symmetric difference for Countersjson.loadgetsarray_hookalongside existingobject_hook, enabling fully immutable JSON parsing withfrozendict+tuple
Chang's view on
ContextDecorator: "This now makes context managers the best way to create decorators — it avoids some of the common footguns and provides cleaner syntax." 12 The free-threading additions (serialize_iterator, concurrent_tee) are worth particular attention for teams exploring Python 3.13+'s experimental no-GIL mode.OpenBSD 7.9 released
Score: 416 pts · Comments: 307 · Submitted: May 19 · HN
Source: 13
The 60th OpenBSD release. Hardware additions include RK3588/RK3576 SoC support, SpacemiT K1 SoC, Apple Silicon SDHC via Genesys Logic GL9755, and AMD EPYC 9005 PSP. 13
Network stack changes:
veb(4) becomes a VLAN-aware bridge with PVID/VID support; pf(4) gains source and state limiters; IPv6 SLAAC enabled by default; 802.11ax basic support added; iwx(4) picks up 160 MHz channel width, powersave, and PMF. Virtualization: SEV confidential computing, 32-bit direct kernel launch, VM sysupgrade via vmboot, Apple Virtualization support. SMP unlocks cover socket splicing, parallel fault handling on amd64/arm64, and IGMP/MLD6 fast timers. Security: __pledge_open syscall for tightly controlled libc file access; root no longer bypasses BPF BIOCLOCK; tmppath pledge capability retired. DRM updated to Linux 6.18.22; USB4 controller driver (nhi) added. 13Performance
Was my $48K GPU server worth it?
Score: 556 pts · Comments: 439 · Submitted: May 18 · HN
Source: 14
Ben Rosmine quit a FAANG job to do independent ML research and built a 6-GPU server (6× RTX 6000 Ada) for $48K. As of March 2026 he has saved $17K versus equivalent cloud rental, and is now saving $90–$105/day at current market rates. Actual GPU utilization averaged 76% overall and 85% since January 2025 — below his 95%+ target, partly due to three downtime incidents from PCIe riser failures and a two-power-supply configuration spread across separate apartment circuits. 14
Rosmine's central observation on the ownership mindset shift: "When renting, each experiment costs money and I had to ask myself is it worth it. When owning, it feels like not running experiments is costing me money." His practical advice for the next build: buy a standard datacenter server and rent colocation space — riser debugging on a custom consumer build is painful. 14
The comment thread explored the alternatives. @freediddy went a different direction — $25K across an M3 Ultra Mac Studio, MacBook Pro M5 Max, and an RTX 6000 Pro — and notes the worst-case scenario is selling within a year for a haircut, not losing the full cloud rental spend. @kgeist reported that a single RTX 5090 serves ~80 developers running Qwen3-32B (a 32-billion-parameter model) at performance close to Claude Sonnet 4.6 on agentic coding tasks. The launch Rosmine built toward ultimately succeeded: 400K+ views and companies reaching out for IP.
AI is killing the cheap smartphone: the global memory crunch
Score: 525 pts · Comments: 607 · Submitted: May 21 · HN
Source: 15
David Oks documents how HBM (High-Bandwidth Memory) demand for AI GPUs has consumed ~20% of global DRAM wafer capacity in 2026, up from 2% in 2023. HBM is three times more wafer-intensive per GB than commodity DRAM, and the three manufacturers controlling 90%+ of global production — Samsung, SK Hynix, and Micron — prefer it for its 70%+ margins versus 20–30% on DDR/LPDDR. 15
The downstream effects on consumer hardware: LPDDR4 prices rose 250% year-over-year; DDR5 in Germany spiked 414% over one year. The sub-$100 smartphone market collapsed 59% year-over-year in India in Q1 2026; Transsion (which holds 48% of the African market) saw profits fall 54%. Micron exited consumer DRAM entirely by discontinuing the Crucial brand; SK Hynix now allocates 30% of wafers to HBM. Nvidia's Vera Rubin platform, expected late 2026, is projected to consume more LPDDR than Apple and Samsung combined by 2027. Oks: "In the space of three years HBM went from a peripheral product category to the very core of the memory industry." The sub-$100 smartphone, he argues, risks becoming "permanently uneconomical." 15
@simonw noted that the headline undersells the article: "This is a fascinating, deep explanation of how the memory market works." @try-working added a structural complication: the Big 3 are effectively super-charging their Chinese competitors CXMT and YMTC by ceding the commodity DRAM segment — a long-term dynamic that could reshape the market if Chinese producers scale. @LeifCarrotson flagged the capital structure: a single DRAM fab costs $15–20 billion, and only three players remain globally.
How fast is N tokens per second, really?
Score: 485 pts · Comments: 96 · Submitted: May 17 · HN
Source: 16
Mike Veerman built a browser-based interactive visualization that renders token streaming at different speeds across four modes: code, text, think (reasoning model), and agent (tool calls with pauses). The core point: code is more token-dense than prose, so the same tok/s rate produces very different subjective experiences by content type. English prose averages ~1.3 tokens per word, so 30 tok/s ≈ 23 words/s. 16
Reference presets in the tool: 5 tok/s (Raspberry Pi local inference), 60 tok/s (hosted Claude/GPT), 200 tok/s (Groq), 800 tok/s (Cerebras). Veerman's framing: "Unless you've actually watched tokens stream at those rates, the numbers are hard to internalize. This is the rendering." 16
@ricardobeat observed that 5 tok/s is faster than human typing but feels slow for agents, while 100–150 tok/s feels too fast to follow. @aurareturn put the era in context: "We truly are in the dial-up era of GenAI." @jerf found it mapped well to 1200 vs. 28.8k baud modem experiences — a perceptual gap the numbers alone never captured.
Antigravity 2.0 tops the OpenSCAD architectural 3D LLM benchmark
Score: 409 pts · Comments: 156 · Submitted: May 22 · HN
Source: 17
ModelRift benchmarked six AI coding tools building the Pantheon from two reference images in OpenSCAD (a text-based parametric CAD language) — a task chosen because OpenSCAD's plain-text model maps to how language models reason about spatial structure as nested transformations. 17
| Tool | Score (out of 5) | Notable behavior |
|---|---|---|
| Google Antigravity 2.0 / Gemini 3.5 Flash High | 4.5 | Searched real Pantheon dimensions; implemented coffered ceiling; included "M AGRIPPA" inscription |
| Claude Code / Sonnet 4.6 | 3.4 | Cleanest proportions; slowest to complete |
| Codex 5.5 High | 3.0 | Densest detail; STL export had geometry problems around portico roof |
| Cursor Composer 2.5 | 1.4 | Fastest; weakest result |
Speed did not predict quality: the fastest tool finished last on quality. The STL export divergence for Codex is a production-relevant failure mode — the preview render loop looked strong, but the final exported geometry didn't match. ModelRift's overall take: "None of these outputs would pass as faithful architectural models… but every system got to valid, renderable OpenSCAD without writing a line of CAD code by hand. The quality gaps between tools are real, but that baseline is higher than we expected." 17
HN commenters debated whether Antigravity's win reflected model quality or prompting advantage, and whether Gemini pricing (a 3× increase over Flash 3.0) is sustainable at that performance level.
Databases
Indexing a year of video locally on a 2021 MacBook with Gemma 4 31B
Score: 463 pts · Comments: 138 · Submitted: May 21 · HN
Source: 18
NJ (SimbaStack) built a local-first video indexing pipeline on a 2021 MacBook Pro M1 Max 64GB, running Gemma 4 31B at Q4 quantization (28.4 GB model size) with 50.89 GB of swap at peak during the bulk indexing run. 18
The pipeline:
ffprobe → exiftool GPS → Nominatim reverse geocode → ffmpeg frame extraction → WhisperX transcription with diarization → insightface face detection → Gemma 4 vision model description → sidecar .description.md per clip. Three vision backends — Claude via Max subscription CLI (default), Anthropic API for speed, LM Studio for bulk passes — with the local 31B closing most of the gap to Sonnet 4.6 except for the hard 10–20% of clips. 18The core architectural insight: "Most of the AI-editor space is competing for the surface above an index that doesn't exist, and the index is the prerequisite they're all skipping past." Enum constraints beat instructions for confabulation prevention — using a structured
lighting enum (golden_hour, bright_daylight, etc.) stopped the model from inventing "brightly lit, abundant natural light" at night. 18@Confiks challenged the memory numbers: Gemma 4 31B at 4-bit quantization should weigh ~19 GiB, not 28.4 GiB, and that much swap will age the SSD measurably. @carpo reported building a similar Electron app with Whisper, ffmpeg, semantic search, and embeddings for chatting with video archives. NJ's summary of the hardware: "I bought it for Chrome. It's running a model that didn't exist when I bought it."
This week's signal
Three distinct themes ran through the week's top posts. First, the developer supply chain is under sustained attack from multiple directions simultaneously — VSCode extension compromise, npm package injection, AWS GovCloud credential exposure, and AI bot flooding of open-source repositories. The tools are different but the vector is the same: trust relationships in developer workflows.
Second, the guardrail-vs-raw-capability debate has a data point now. Forge's result — a local 8B model beating a frontier API through structured retry logic — is a concrete argument that reliability infrastructure is where the ceiling on local model usefulness currently sits, not raw parameter count.
Third, the memory repricing story in the smartphone market is the slowest-moving but highest-impact item of the week. The DDR/LPDDR supply squeeze driven by HBM demand is not a short-term spike; it's a structural shift with a multi-year timeline that will reshape hardware economics well beyond AI.
References
- 1GitHub confirms breach of 3,800 repos via malicious VSCode extension
- 2GitHub is investigating unauthorized access to their internal repositories
- 3Incident Report: Railway Blocked by Google Cloud (resolved)
- 4Incident Report: May 19, 2026 – GCP Account Suspension
- 5Mini Shai-Hulud Strikes Again: 314 npm Packages Compromised
- 6CISA Admin Leaked AWS GovCloud Keys on GitHub
- 7We stopped AI bot spam in our GitHub repo using Git's --author flag
- 8Show HN: Forge – Guardrails take an 8B model from 53% to 99% on agentic tasks
- 9Project Glasswing: An Initial Update
- 10Everything in C is undefined behavior
- 11Show HN: Semble – Code search for agents that uses 98% fewer tokens than grep
- 12Python 3.15: features that didn't make the headlines
- 13OpenBSD 7.9
- 14Was my $48K GPU server worth it?
- 15AI is killing the cheap smartphone
- 16How fast is N tokens per second really?
- 17Antigravity 2.0 Tops the OpenSCAD Architectural 3D LLM Benchmark
- 18Indexing a year of video locally on a 2021 MacBook with Gemma4-31B (50GB swap)
Add more perspectives or context around this Post.